
5 motivi per scegliere un database a grafo - RIOS
5 motivi per scegliere un database a grafo
05 maggio 2023
Introduzione
Con il tempo la produzione sempre più massiccia di dati ci ha condotto allo scenario che osserviamo oggi, in cui a farla da protagonisti sono i Big Data.
I database relazionali non sono sufficientemente performanti quando si tratta di gestire grandi quantità di dati in continuo aumento e nasce, quindi, l’esigenza di tecnologie innovative per salvare e analizzare questi dati.
Per questo motivo, preferiamo i database non relazionali che stanno avendo sempre più successo poiché, rispetto ai più comuni database relazionali, presentano molti vantaggi e consentono, ad esempio, di avere uno schema flessibile.
In questo articolo parleremo di un database non relazionale in particolare: il Database a Grafo, anche detto Graph DB. Analizzeremo il suo potenziale e presenteremo cinque motivi per cui il database a grafo è il più efficiente.
Il Database a Grafo
Un grafo è composto da due elementi: nodi e relazioni.
Ogni nodo rappresenta un'entità e ogni relazione fornisce collegamenti nominati e diretti tra due entità nodo (ad esempio, Persona AMA Persona).
Possiamo marcare i nodi con etichette che rappresentano i loro diversi ruoli nel dominio (Persona, Auto) e possono contenere proprietà (nome, nascita, twitter ecc.). Le relazioni hanno sempre una direzione, un tipo, un nodo iniziale e un nodo finale. Possono inoltre avere proprietà, proprio come i nodi.
Possiamo usare i grafi per rappresentare numerosi tipi di dati. Possono essere dati provenienti da una rete sociale o, in generale, da tutti i casi in cui le relazioni giocano un ruolo chiave.
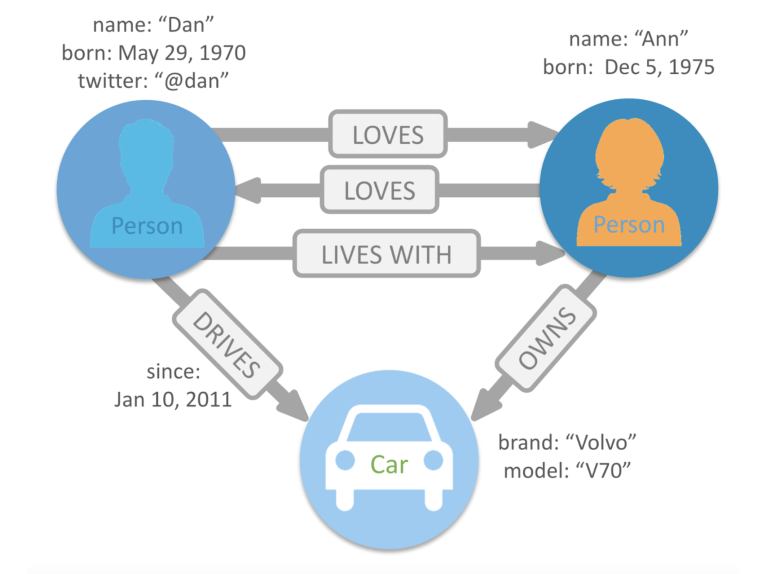
Esempio di grafico preso da neo4j.
I database a grafo memorizzano nodi e relazioni invece di tabelle o documenti e preferiscono le relazioni.
Un database a grafo è un sistema di gestione di database online che utilizza operazioni CRUD e funziona su modelli di dati a grafo.
Inoltre, possiamo applicare i database a grafo a diversi settori e scopi. Aiutano ad analizzare le informazioni interconnesse e a comprendere, valutare e sfruttare i processi e le relazioni.
Infine, questi database sono ideali per l'analisi del rischio e il rilevamento di frodi ed errori.
5 motivi per passare a un database a grafo
1.Flessibilità
I database a grafo sono progettati per salvare i dati senza limitarli a un modello fisso. Infatti, non abbiamo uno schema predefinito.
Sono costruiti sulle proprietà del modello a grafo che non impone vincoli relazionali. Per questo motivo, eventuali futuri cambiamenti saranno più facili e veloci da applicare poiché non abbiamo bisogno di modificarne il modello. Ciò li rende quindi anche affidabili per il salvataggio dei dati in tempo reale.
Con il passare del tempo i dati stanno diventando sempre più complessi e allo stesso modo i database a grafo si rivelano sempre più indicati per la maggior parte dei casi d'uso, soprattutto quelli in cui la manipolazione dei dati è prioritaria.
Inoltre, poiché per funzionare non devono formalmente rispettare regole vincolanti, possiamo usarli per rappresentare qualsiasi origine di dati.
2.Scalabilità
I dati crescono costantemente, per questa ragione le applicazioni non possono essere vincolate al loro volume. Devono invece scalare per poter gestire volumi di dati più elevati mantenendone al contempo prestazioni e integrità.
Tra le altre cose, i database a grafo sono utili perché ci consentono di fare proprio questo. È possibile ottenere ottime prestazioni anche su miliardi di nodi e trilioni di relazioni con tempi di risposta rapidi.
È possibile aggiungere alla struttura attuale senza interrompere la funzionalità esistente. Grazie alla loro natura distribuita, i database a grafo consentono sempre un’adeguata scalabilità (orizzontale o verticale).
La scalabilità verticale è la potenzialità di aumentare la capacità operativa aumentando la capacità di un singolo server al fine di soddisfare maggiori richieste operative. Questo potrebbe includere l'aggiunta di più dischi, memoria o potenza di elaborazione a un server.
La scalabilità orizzontale è la potenzialità di aumentare la capacità operativa aggiungendo server aggiuntivi. I server stessi possono essere di grandi dimensioni, ma possono anche essere commodity server più economici.
3.Visualizzazione più chiara
Come abbiamo già detto, i database a grafo preferiscono le relazioni. Per questo motivo, con essi è più facile e intuitivo navigare tra i dati rispetto ai database relazionali e alle classiche tabelle. Basta pensare ai dati di un social network. Se salviamo tutte le informazioni degli utenti in tabelle, perdiamo tutte le connessioni tra di loro. Successivamente, durante un'analisi, sarebbe più difficile recuperare queste informazioni.
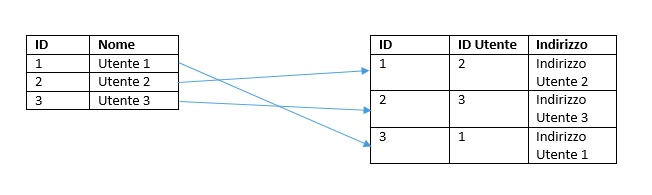
Fonte: RedBlue’s Blog
Invece, salvando i dati in un database a grafo, manteniamo le connessioni tra di loro. Grazie alla loro correlazione, possiamo recuperarle in modo più semplice e rapido, navigando anche a livelli più profondi.
Ad esempio, partendo da un singolo nodo, possiamo costruire il grafo indotto da quel nodo semplicemente espandendolo e quindi recuperare tutte le connessioni con gli altri nodi all'interno della rete.
La struttura grafica, a differenza di quella tabellare nei database relazionali, consente una visualizzazione completa, accessibile e comprensibile a tutti gli utenti, anche i meno esperti.
Esempio di espansione del grafo eseguita su Galileo.XAI
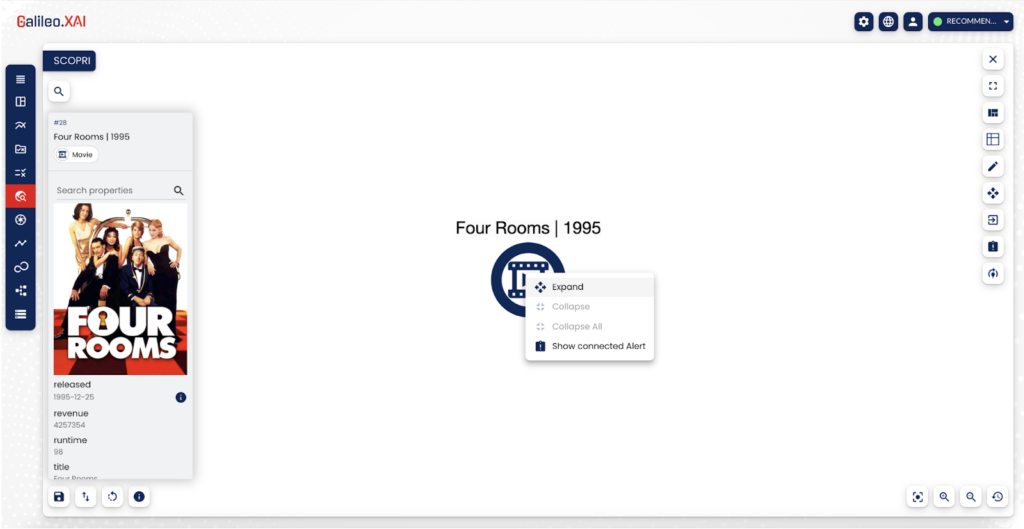
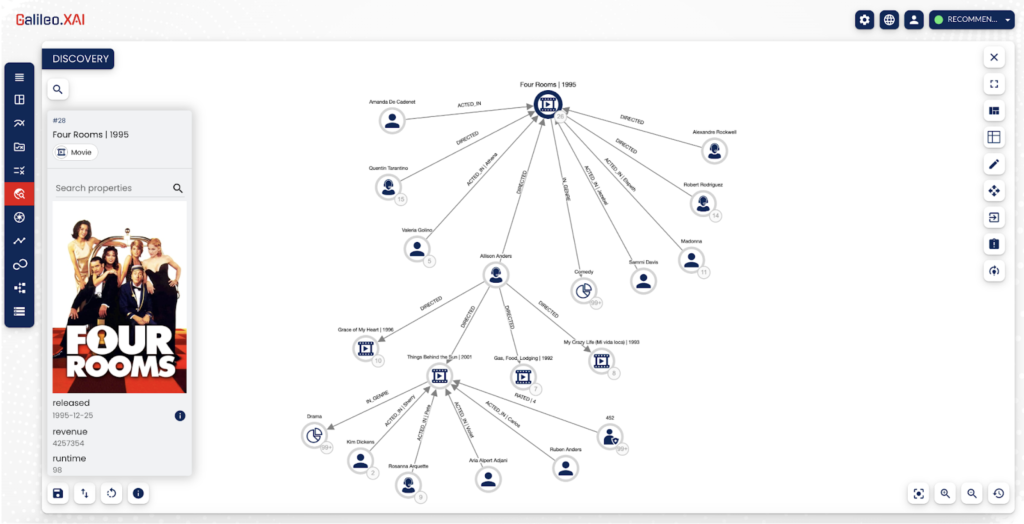
💡Nell'esempio proposto, partendo dal film "Four Rooms" possiamo facilmente espandere il nodo e decidere di fermarci quando abbiamo raggiunto il sottografo di interesse.
4.Query più veloci
Viviamo in un mondo connesso in cui le relazioni tra gli elementi sono importanti tanto quanto gli elementi stessi.
Nonostante i database relazionali esistenti siano in grado di archiviare le relazioni tra le entità, riescono a navigarle solo attraverso operazioni costose o ricerche incrociate, spesso legate a uno schema rigido.
Per creare relazioni tra più entità in un database relazionale sarebbe necessario introdurre una tabella di entità associativa che contenga le chiavi esterne di entrambe le tabelle partecipanti. Questo aumenta ulteriormente i costi delle operazioni di unione.
In un database a grafo, invece, le relazioni sono archiviate nativamente con i nodi in un formato molto più flessibile.
Tutto il sistema è ottimizzato per passare rapidamente attraverso i dati. Il database a grafo ci permette quindi di risparmiare molto tempo in quei casi in cui abbiamo bisogno di interrogare il database e ottenere informazioni sui dati connessi. Inoltre, possiamo ottenere risultati con operazioni molto meno costose rispetto alle query che sarebbero necessarie per ottenere le stesse informazioni da un database basato sul modello tabellare.
L'esempio seguente è tratto da Neo4j:
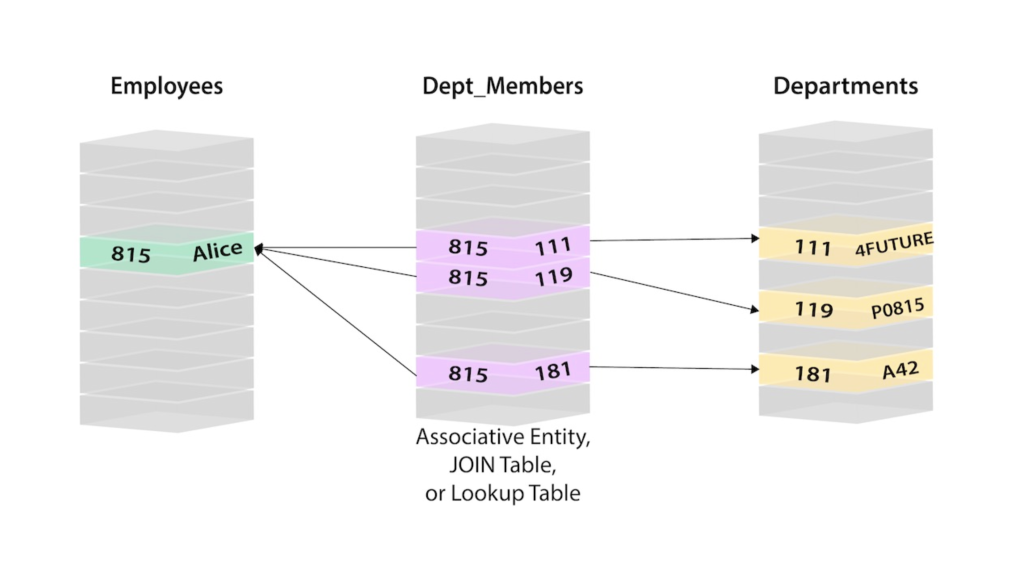
In questo caso, per recuperare le informazioni su Alice, si dovrebbe cercare l'utente Alice e il suo ID persona 815 nella tabella degli impiegati (Employees) a sinistra. Successivamente, nella tabella dei membri del dipartimento (Dept_Members), si dovrebbero trovare tutte le righe che si riferiscono all'ID persona di Alice (815). Quindi si andrebbero a recuperare le tre righe pertinenti per poi spostarsi alla tabella dei Dipartimenti (Departments) a destra. Lì si potrebbero infine cercare i valori effettivi degli ID dei dipartimenti (111, 119, 181).
Si arriverebbe quindi a sapere che Alice appartiene ai dipartimenti 4Future, P0815 e A42 solo dopo aver eseguito tutte le operazioni descritte.
È facile capire quanto queste connessioni siano complesse. In questo caso, dovremmo prima conoscere i valori dell'ID persona e dell'ID dipartimento (effettuando ulteriori ricerche per trovarli) per sapere quale persona è collegata a quali dipartimenti.
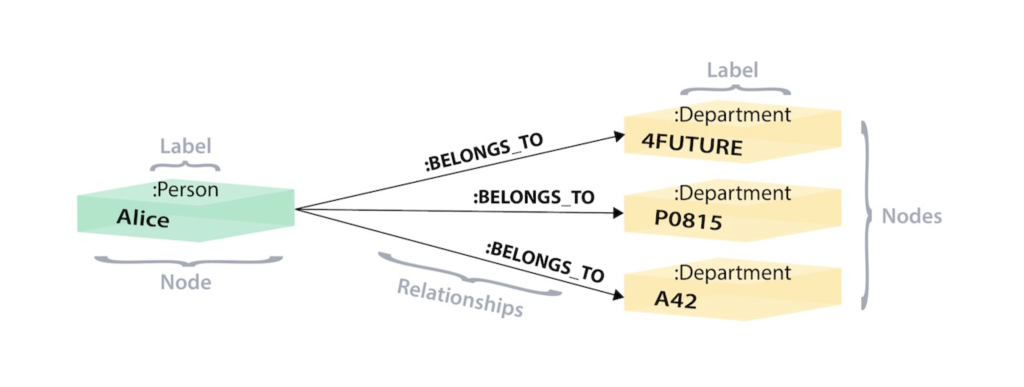
Nella versione a grafo, abbiamo invece un singolo nodo per Alice con un'etichetta Persona. Alice appartiene a 3 diversi dipartimenti, quindi non rimane che creare un nodo per ognuno di essi con un'etichetta di tipo Dipartimento.
Per scoprire a quali dipartimenti appartiene Alice è sufficiente cercare il nodo Alice nel grafo e, attraversando tutte le relazioni BELONGS_TO che partono da Alice, arrivare ai nodi del dipartimento a cui è collegata.
Questo è tutto ciò di cui abbiamo bisogno: un singolo salto senza ricerche coinvolte.
5.Analisi dei dati
I database a grafo hanno uno strumento potente per l'analisi dei dati, ovvero la capacità di applicare algoritmi sui grafi.
Questi algoritmi ci danno l'opportunità non solo di studiare come è strutturata la rete, ma anche di capire quanto importanti o simili sono alcuni nodi al suo interno. Ad esempio, possiamo analizzare il ruolo svolto da nodi più centrali rispetto a quelli più periferici. Possiamo investigare le interazioni tra di loro o studiare le comunità legate a nodi con caratteristiche simili.
Tra i vari algoritmi disponibili per i database a grafo, ci concentriamo sulla Centralità e sulla Rilevazione delle Comunità.
La combinazione di queste analisi ci consente di trovare pattern all'interno della rete e di evidenziare situazioni che possono essere significative in linea con il caso d'uso analizzato.
Centralità
Possiamo utilizzare gli algoritmi di centralità per determinare l'importanza di nodi distinti in una rete. I nodi possono essere classificati come più o meno importanti in base alle loro interazioni con altri nodi. Ogni nodo nella rete riceverà quindi un punteggio di importanza: maggiore è l'importanza, più è alto è il punteggio.
In alcuni casi abbiamo dei nodi chiamati "broker". La loro rimozione dal grafo comporterebbe una disconnessione totale o parziale della rete.
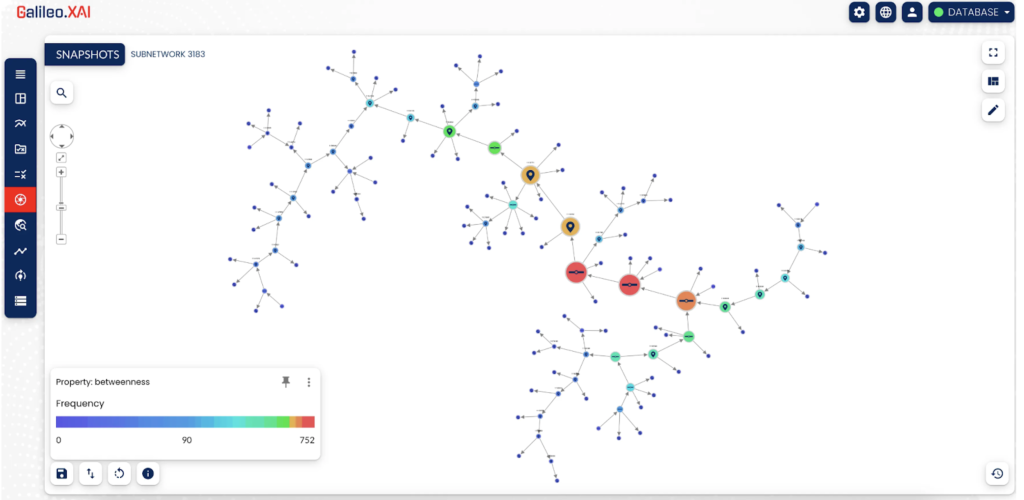
In questo esempio di Galileo.XAI misuriamo l'importanza di un nodo in base al flusso di informazioni che lo collega a tutti gli altri nodi della rete.
L'algoritmo applicato è il Betweenness Centrality della Graph Data Science di Neo4j. Possiamo usarlo per trovare i nodi che fungono da ponte da un lato all'altro.
Anche attraverso la mappa termica in basso a sinistra, si può vedere quali nodi sono più o meno importanti in base al loro punteggio. Più alto è il punteggio, più importante è il nodo.
In questo caso, i nodi in rosso sono i più importanti della sottorete rappresentata. È facile capire il perché. Se cancelliamo questi nodi, disconnettiamo la sottorete e perdiamo le comunicazioni tra i nodi.
Rilevamento delle comunità
Possiamo usare gli algoritmi di rilevamento delle comunità per valutare come i gruppi di nodi sono raggruppati o suddivisi, nonché la loro tendenza a rafforzarsi o separarsi.
Solitamente, i nodi raggruppano altri nodi in una comunità in base alle loro interazioni.
Ogni comunità è composta da nodi che hanno molte interazioni e che sono quindi densamente collegati. Questo tipo di algoritmi aiuta a capire meglio la struttura della rete, poiché attraverso le comunità possiamo capire quali sono i nodi che interagiscono di più e quelli che interagiscono meno e quindi si trovano in comunità diverse.
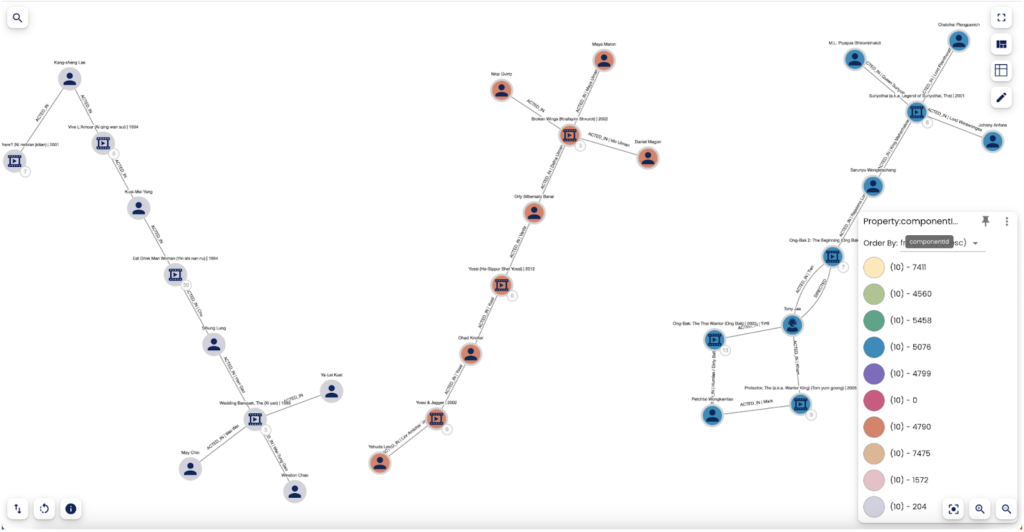
In questo esempio, mostrato grazie a Galileo.XAI, abbiamo applicato l'algoritmo Weakly Connected Components della Graph Data Science di Neo4j per trovare insiemi di nodi collegati nei grafi. Possiamo quindi studiare le connessioni della rete e la suddivisione della rete in comunità per rappresentare sottoreti.
Nel Weakly Connected Components (WCC), due nodi sono collegati se c'è un percorso tra di loro indipendentemente dalla direzione della relazione.
Una comunità è rappresentata da un insieme di tutti i nodi che sono collegati tra loro.
La figura sopra rappresenta tre tra i componenti connessi totali trovati nell'intera rete.
Oltre agli algoritmi principali, per i database a grafo ci sono anche algoritmi di incorporamento dei nodi che sono tipicamente utilizzati come input per le attività di machine learning successive, come la classificazione dei nodi, la previsione dei collegamenti e la costruzione di grafi di somiglianza kNN.
Giocano quindi anche un ruolo importante nel campo del Machine Learning e dell'Intelligenza Artificiale, di grande importanza al giorno d'oggi.
Conclusioni
In conclusione, abbiamo visto come in un mondo in cui i dati stanno crescendo in modo esponenziale, cambiando rapidamente e con una struttura che non sempre è fissa, esiste concretamente la necessità di una struttura dati a grafo.
Oggi con un grafo possiamo rappresentare praticamente tutto ciò che ci circonda. Pensate a internet, ai social network o alle reti di comunicazione come a una mappa della città.
I database a grafo ci consentono di gestire facilmente le relazioni temporali all'interno di una rete, soprattutto per quei modelli in tempo reale che necessitano frequenti aggiornamenti.
Inoltre, vengono sempre più utilizzati perché sono indispensabili per l'applicazione dell'analisi di Machine Learning e Intelligenza Artificiale.
Ci troviamo quindi di fronte a un modello innovativo che sta diventando sempre più importante e che rappresenta un supporto fondamentale per la scienza delle reti.
Quindi, non ci resta che dire, studiamo i database a grafo e sfruttiamo il loro potenziale!
Se vuoi scoprire di più sul mondo delle connessioni la rete RIOS ti offre la competenza e l’esperienza di LARUS, premier partner del leader dei database a grafo, Neo4j, dal 2014!
Contattaci per approfittare di tutte le opportunità di formazione e approfondimento che possiamo offrirti.